Making a Movie Recommendation App with Python and Beautiful Soup

Hey there! I'm passionate about Computer Science, and all things related to Mathematics. As someone who loves to share knowledge, I regularly host sessions on various computer science and math topics, helping people conquer their fears and embrace the beauty of these subjects.
What is Web Scraping?
Let's say you want a list of 100 top-rated doctors in your area. You can just search online and write them down 1 by 1. Even if you find a website containing all 100 of them in one place. They might have extra unnecessary info that you can't just ctrl+C, ctrl+V. It would take a long time. What if you could just use the website link and download all the names of the doctors at once?
Web scraping allows you to do just that. A web scraper is just like an assistant whom you can give a task like: "Hey, go through all the names on the website and find out how many of them are doctors."
Your assistant doesn't read every single item from top to bottom. Instead, it quickly scans the content, picks out the sentences or paragraphs about doctors, and brings them back to you. That's web scraping in action.
In short, web scraping is a method of collecting data. It makes it easier to collect and store massive amounts of data in a short amount of time which would otherwise take a lot of time and will be incredibly tedious.
How I Used Python to Scrape and Randomize My Letterboxd Watchlist
I love watching movies, and I use Letterboxd to keep track of the films I want to watch. However, sometimes I have trouble deciding what to watch next because my watchlist is too long. I wanted to find a way to make my movie selection more fun, so I decided to write a Python script that scrapes my watchlist and prints a random movie title from it. This way, I can get a surprise recommendation every time I run the code.
In this blog post, I will show you how I did it, and what kind of movies I got from my randomizer. To follow this blog, you must have a fundamental understanding of HTML.
Python: Your Versatile Web Scraping Companion
Python is a champion for web scraping. It offers a powerful yet beginner-friendly toolkit. Let's go over all the basic tools we will use for web scraping. Don't worry if you don't know what the library does. You will learn them along the way. Let's just build something.
Python: Obviously!
Requests: This library acts as your web browser, sending requests to websites and fetching their content. You can learn more about the library here -> Requests
Beautiful Soup: This library transforms messy HTML code into a structured format. Making data extraction extremely easy.
Random: A module that lets us generate random numbers and choices.
The Plan
The plan for this project is quite simple and short. It consists of three main parts:
Importing the libraries
Scraping the watchlist
Printing a random movie title
Let’s look at each part in detail.
Importing the Libraries
The first part of the code is importing the libraries that we need:
import requests
from bs4 import BeautifulSoup
import random
We use the
importstatement to import the modules and libraries into our program.We also use the
fromkeyword to import specific functions or classes (it's okay if you don't know what classes are).
Scraping the Watchlist
The second part of the code is scraping a user's watchlist on Letterboxd. For this example, I will use my watchlist, but you can replace the URL with any user’s watchlist that you want to scrape.
We start by creating an empty list called
datathat will store the movie titles.data = []Then, we use a
whileloop to iterate over the web pages of the watchlist.data = [] while True:We use the
requests.get()function to send a GET request to the URL and get the HTML content of the page. Then we store it in a variable called response.We use the
BeautifulSoup()function to create a soup object that represents the HTML document as a nested data structure. (It structures the HTML doc for normal humans to understand)data = [] while True: response = requests.get('https://letterboxd.com/ashfin/watchlist/') soup = BeautifulSoup(response.text, 'html.parser')Next, we have to go to our website and find our desired elements.
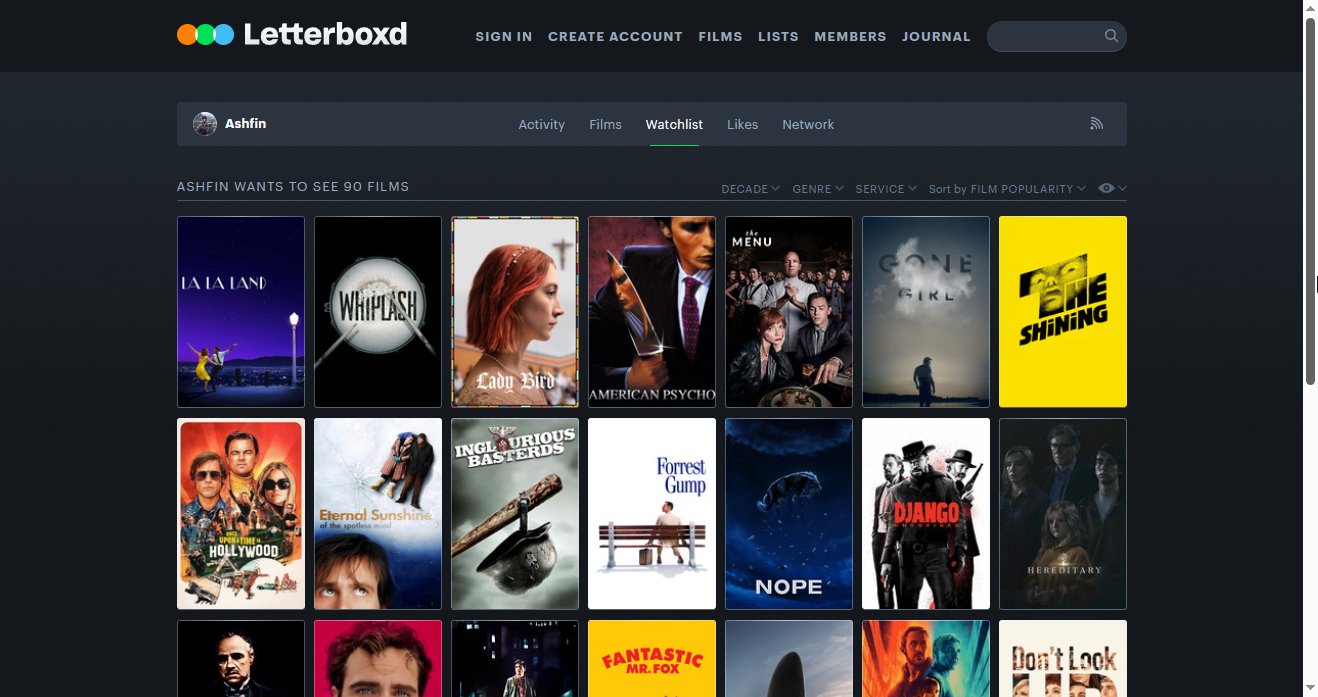
We right-click on the page and select Inspect Element. This allows us to inspect the HTML file
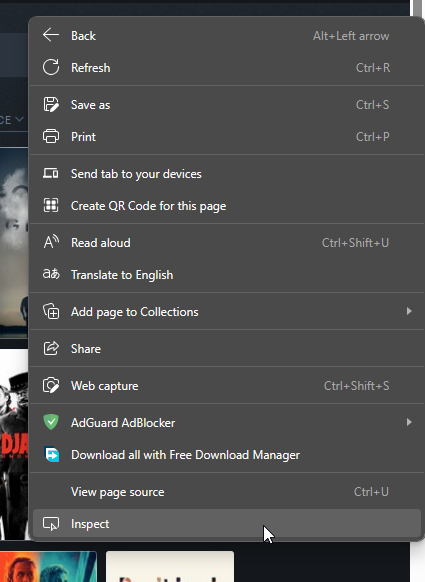
Remember that this might be different for different browsers.
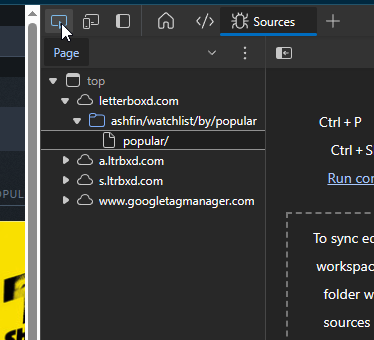
We click on the Select Element button and try to find the movie's title.
The titles might not be as easily accessible on some sites so you would have to do some digging. In our case, we can find the title from the
altattribute of the movie images.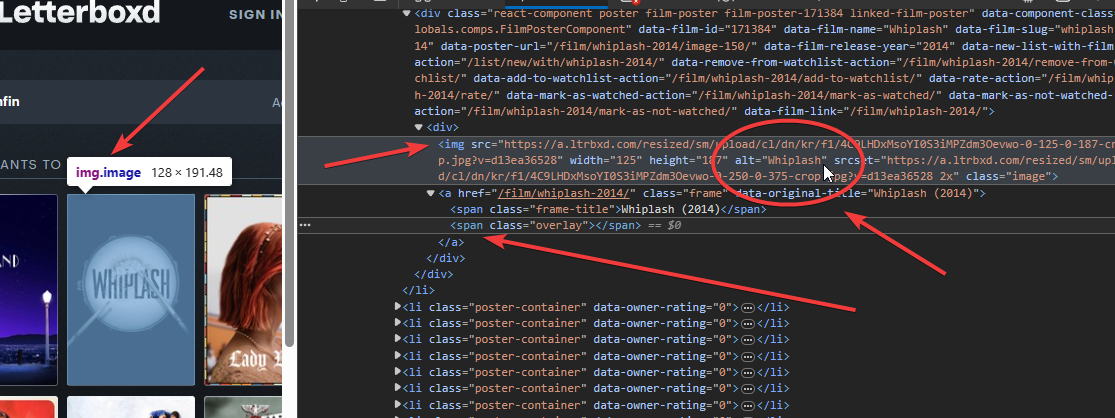
We use the
soup.select()method to find all the elements that match the CSS selectorli.poster-container. Since the image attribute is inside theli.poster-containerattribute.This selector returns a list of items containing the movie posters and titles.
We use a
forloop to iterate over this list, and for each element, we find theimgtag inside it.for e in soup.select('li.poster-container'): img = e.find('img')We use the
has_attr()method to check if theimgtag has analtattribute, which contains the movie title. If it does, we use theappend()method to add the title to thedatalist.for e in soup.select('li.poster-container'): img = e.find('img') if img and img.has_attr('alt'): data.append(img['alt'])
Printing a Random Movie Title
The third and final part of the code is printing a random movie title from the data list.
We use the
random.randint()function to generate a random integer between 0 and the length of the list. We use this integer as the index to access a random element from the list.num = random.randint(0, len(data))We use the
print()function to display the movie title on the screen.num = random.randint(0, len(data)) print(data[num])We also use the
input()function to ask the user if they want to exit the program or continue. If the user types 1, the program breaks out of the loop and ends. Otherwise, the program repeats the process and prints another random movie title.Here's what the final code looks like ->
import requests
from bs4 import BeautifulSoup
import random
data = []
while True:
response = requests.get('https://letterboxd.com/ashfin/watchlist/')
soup = BeautifulSoup(response.text, 'html.parser')
for e in soup.select('li.poster-container'):
img = e.find('img')
if img and img.has_attr('alt'):
data.append(img['alt'])
num = random.randint(0, len(data))
print(data[num])
exit_value = input("type 1 to exit: ")
if exit_value == '1':
break
The Results
Now that we have written the code, let’s see what kind of movies we get from our randomizer. Here are some examples of the output:
Parasite
type 1 to exit:
The Shawshank Redemption
type 1 to exit: 1
As you can see, the randomizer gives us a variety of movies from different genres, years, and countries. Some of them are classics, some of them are recent hits, and some of them are hidden gems. They all reflect my taste and preferences, as they are from my watchlist. This is a fun and easy way to discover and enjoy new movies.
Conclusion
I hope you enjoyed this project and learned something new from it. If you want to try it yourself, you can find the source code here -> Letterboxd-Lifesaver. You can also modify the code to scrape other websites or to add more features or functionality. Just be careful and check if the website allows web scraping or not. Feel free to share your feedback or suggestions in the comments below.
Happy coding and happy watching! 🎬




